

Kubernetes is the number one go-to container orchestration tool. But like any complex system, Kubernetes encounters error scenarios like the frustrating CrashLoopBackOff.
In this tutorial, you will understand the reasons behind the CrashLoopBackOff error. Equip yourself with effective troubleshooting strategies to identify and fix the underlying causes of this dreadful error.
Conquer the CrashLoopBackOff errors and keep your deployments in good shape!
Prerequisites
Before diving into the hands-on demonstrations, ensure you have the following in place:
- Kubernetes installed on your system.
- A running Kubernetes cluster.
Fixing Misconfigurations Causing CrashLoopBackOff Errors
Typically, when you deploy a resource to a Kubernetes cluster, you do not know the exact procedures and lifecycle of how a resource was deployed. The good news is that Kubernetes will always record the status and steps executed to create different containerStatuses.
The PodStatus leaves trails for containers in the Pod that are initialized successfully, running, waiting, or terminated. These recorded statuses let you quickly run a command that troubleshoots the conditions of a Pod.
To see how to troubleshoot a CrashLoopBackOff error in action:
1. Create a deployment.yml file with your preferred editor, and add the configuration below.
The following is purposely misconfigured with a faulty command (command: ["sh", "-c"]) to replicate a CrashLoopBackOff error.
apiVersion: apps/v1
kind: Deployment
metadata:
# Deployment name
name: crashloop
spec:
# Number of instances of the pod
replicas: 1
selector:
matchLabels:
# Selector matching Deployment pods
app: crashloop
template:
metadata:
labels:
# Labeling pod template
app: crashloop
spec:
containers:
# Container name
- name: crashloop-example
# Docker image
image: nginx:latest
ports:
# Container port
- containerPort: 80
# Faulty container command
command: ["sh", "-c"]2. Next, open your terminal or PowerShell as administrator, and run the following kubectl command.
This command lets you apply your deployment configurations to create a Kubernetes cluster as defined in your deployment.yml file.
kubectl apply -f deployment.yml
3. After deployment, execute the kubectl get command below to view (get) all pods.
kubectl get podsBelow, your current Pod shows the CrashLoopBackOff status and is not ready (0/1) to run your container, and the kubelet restartPolicy restarted your Pod at least once.
The CrashLoopBackOff status constantly keeps Pods in a restart loop to stabilize and run the container successfully. If the restart attempt fails, the PodStatus API object enters a CrashLoopBackOff state.
Note down your Pod’s name for later use in digging into the CrashLoopBackOff error.

4. Now, replace the configuration in your deployment.yml file with the one below.
Since the container command has been fixed, this configuration spins up a minimal Kubernetes cluster using NGINX.
apiVersion: apps/v1
kind: Deployment
metadata:
# Deployment name
name: crashloop2
spec:
# Number of instances of the pod
replicas: 1
selector:
matchLabels:
# Selector matching Deployment pods
app: crashloop2
template:
metadata:
labels:
# Labeling pod template
app: crashloop2
spec:
containers:
# Container name
- name: crashloop2-example
# Docker image
image: nginx:latest
ports:
# Container port
- containerPort: 80
# Container command - Fixed
command: ["nginx", "-g", "daemon off;"]5. Rerun your deployment command below to apply the changes to your deployment.yml file.
kubectl apply -f deployment.yml
6. Lastly, run the following command to get all pods to verify your Pod’s status.
kubectl get podsIn this instance, the STATUS is Running with zero (0) RESTARTS, as shown below, and your Pod is currently scheduled on a node. The Kubernetes API has accepted its container, and the application is running as expected in your Kubernetes cluster.

Examining the CrashLoopBackOff Status of Pods
CrashLoopBackOff tells you Kubernetes has tried to restart your Pods repeatedly. The restart causes the container to enter a loop of crashing and restarting, failing to start. But up to this point, you still have no clue about the main reason behind the CrashLoopBackOff error.
You must resolve the crashing behaviors and start your Pod as expected. The conditions commands let you get detailed information about a specific Pod, dig deeper into a given pod, and check its events.
To examine the CrashLoopBackOff status of your Pods:
Execute the command below to describe the information associated with your pod.
Replace pod_name with the one you noted in step three of the “Fixing Misconfigurations Causing CrashLoopBackOff Errors” section.
kubectl describe pod pod_name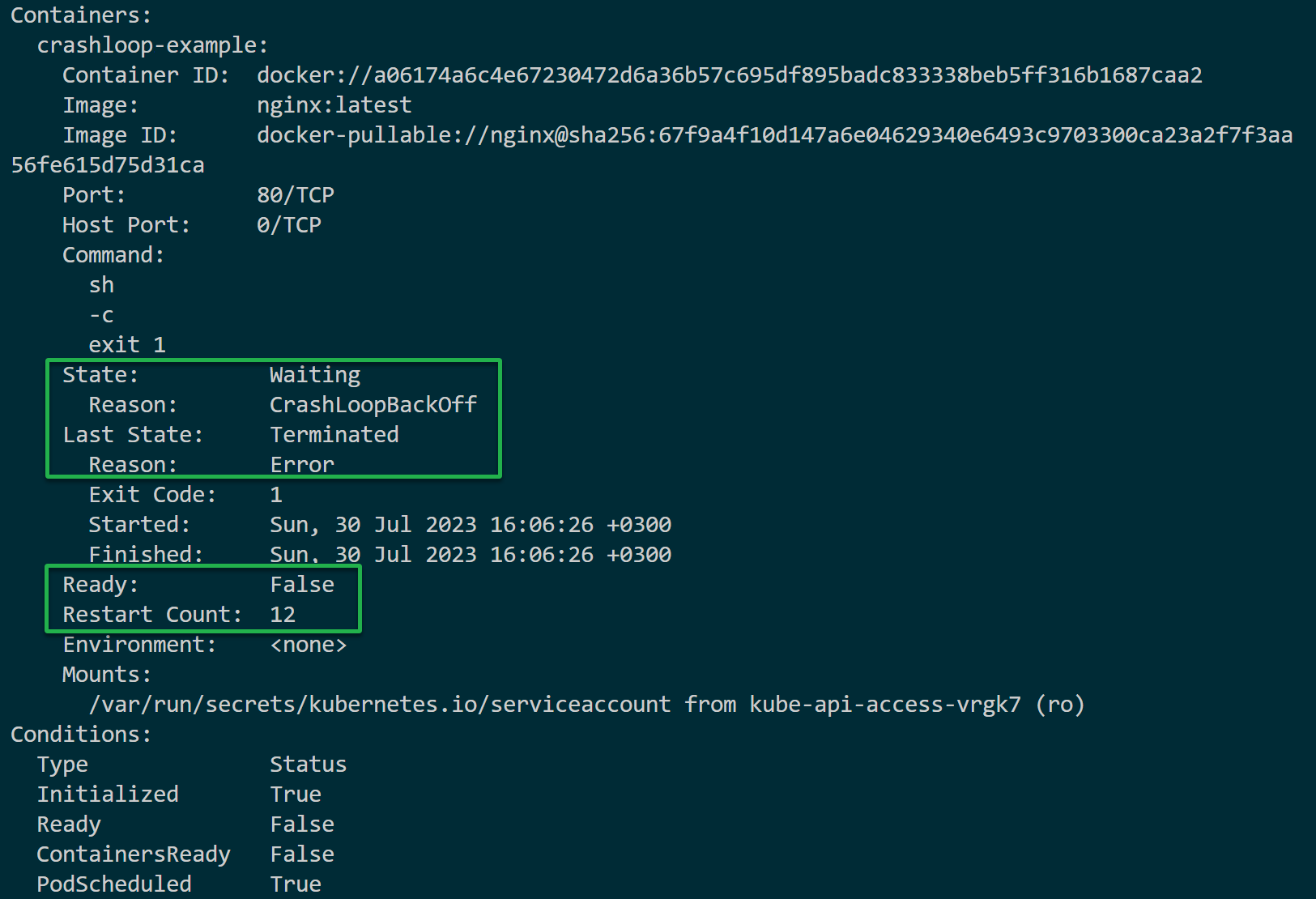
Under Events, you will see a Back-off restarting failed container message recorded by the kubelet. This message indicates the container is not responding and is in the process of restarting.

Preventing CrashLoopBackOff Errors From Arising
You have just fixed the CrashLoopBackOff error, but not getting this error at all would be much better — as the saying goes, “Prevention is better than cure.”
But how do you prevent this error from ever arising? First, you must understand the common causes of the container failing to start correctly and repeatedly crashing.
1. Ensure you have enough resources to spin up your cluster.
Assuming your container has the following specs in your cluster, you tried to deploy a container with resources (memory and CPU) beyond what was specified.
Since your cluster has limited resources, the container is killed due to resource limits. The container fails to start in a loop that forces its crash, resulting in a CrashLoopBackOff error.
containers:
# Container name
- name: container
# Docker image
image: your-image
# Container resource limits
resources:
limits:
# Maximum memory
memory: "1Gi"
# Maximum CPU usage
cpu: "1000m"2. Next, check for an issue with your image.
An image with missing packages, dependencies, and wrong Environment Variables will not run in a Kubernetes cluster.
Config loading errors in Entrypoint and CMD are executed in your image itself. The server running inside the container will fail to load the script’s wrong format, failing to start in CrashLoopBackOff.
3. Fix misconfigurations and typos in your Dockerfiles.
Suppose you use the Dockerfile below, where the path does not exist in the container, or the file system permissions within the container are set incorrectly. The cluster that uses this image will fail to access such files in a continuous loop of crashes.
FROM nginx
COPY nginx.conf /etc/ngin/nginx.conf4. Verify that there are no container port conflicts like in the configuration below.
When creating a cluster that runs a container binding an existing port, the current container will fail to start its pods.
The same scenario happens when using locked files and databases. Trying to access resources locked by another pod means you cannot establish a connection to the locked resources.
containers:
# Frontend container binding to port 80
- name: frontend
image: your-image
ports:
- containerPort: 80
# Backend container attempting to bind to the same port, 80
- name: backend
image: your-image
ports:
- containerPort: 805. Keep your Pods updated simultaneously in a StatefulSet as you make changes without messing up the availability of running Pods or services. Constantly updating clusters spark requirements errors that will likely cause CrashLoopBackOff failures.
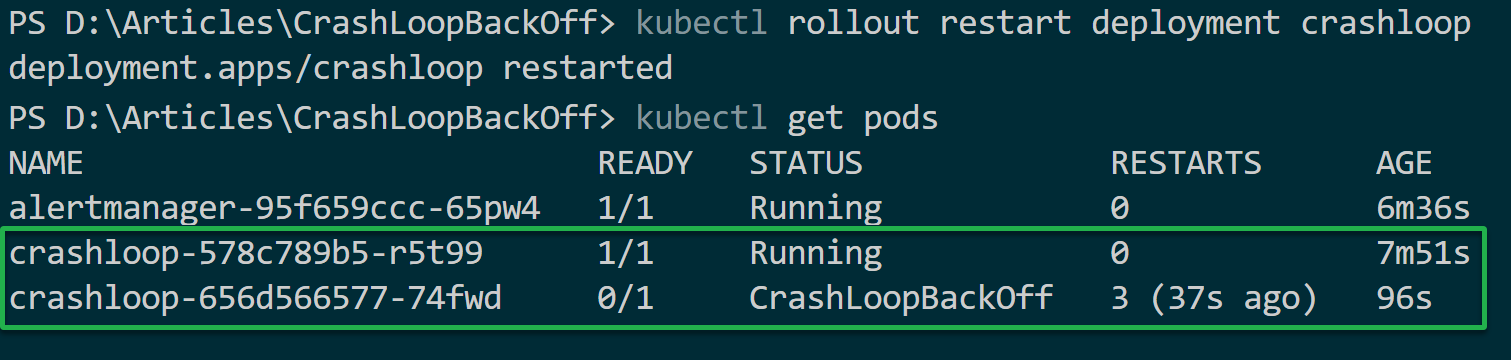
Execute the following commands to roll out updates, restart your deployment (deployment_name), and check (get) all running pods.
# Roll out updates for Pods simultaneously
kubectl rollout restart deployment deployment_name
# Getting the list of all Pods
kubectl get podsIf the new update causes the CrashLoopBackOff error, the older Pods will still run with no downtime as you debug the root cause of the exciting pods CrashLoopBackOff. In such cases, the health and status of your pods and containers require monitoring.
Conclusion
Throughout this tutorial, you have learned how to troubleshoot a CrashLoopBackOff error and how it occurs in Kubernetes deployments. Confidently, you can now identify the root cause of the error, such as resource constraints or configuration issues. Armed with this knowledge, you can make the right changes to mitigate the CrashLoopBackOff error.
Now, why not explore beyond addressing container crashes and start monitoring your Kubernetes cluster? Turn to Grafana and Prometheus to get the upper hand in addressing errors and events executed in any cluster!


